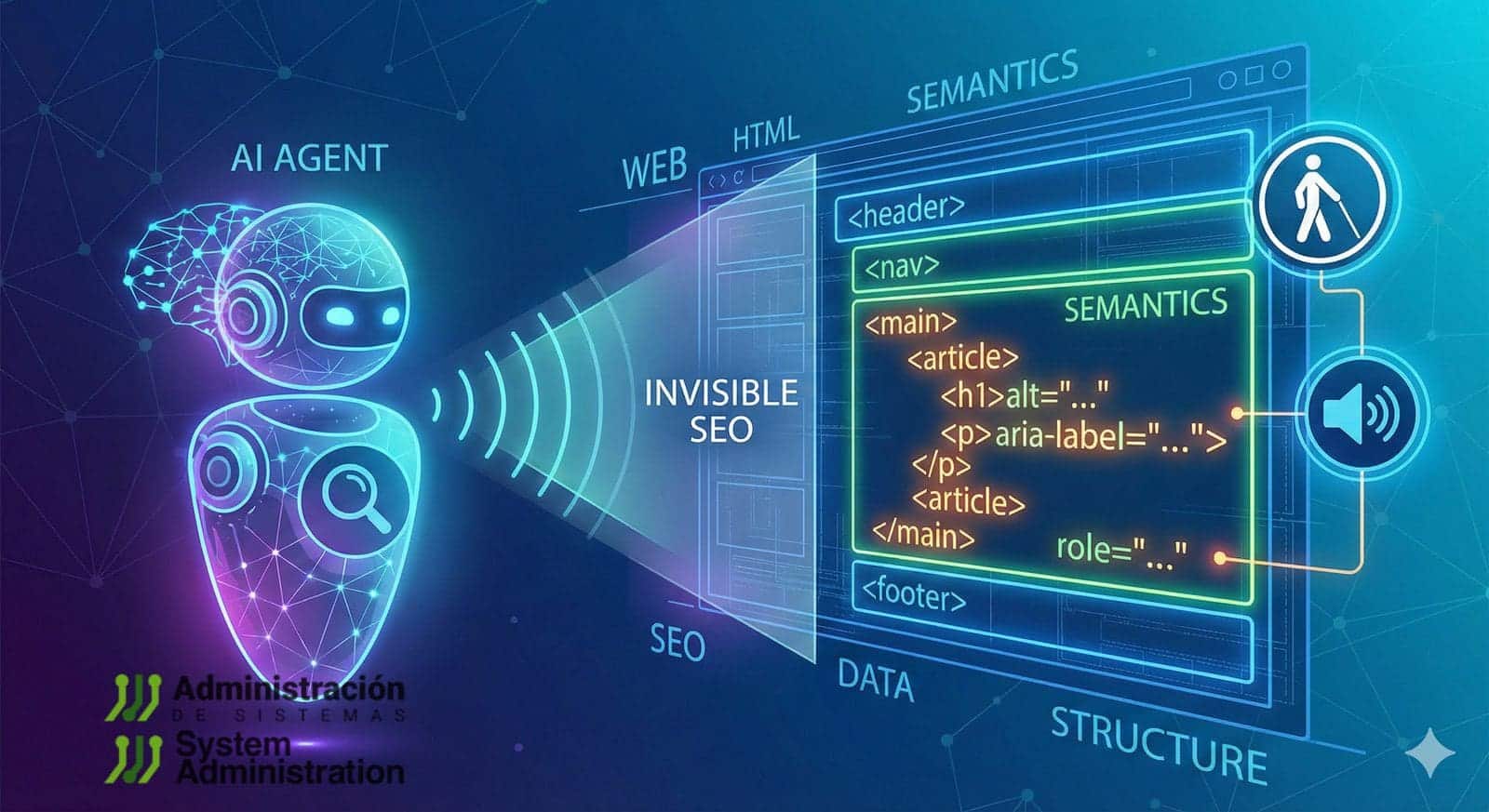
Durante años, hablar de accesibilidad web y de “HTML semántico” sonaba, para parte del público, a un asunto técnico o a algo reservado a personas con necesidades específicas. En 2026, ese debate vuelve por un motivo inesperado: la web está empezando a ser recorrida por agentes de Inteligencia Artificial.
No se trata solo de chatbots que responden preguntas. Cada vez más, estos agentes intentan leer páginas, entender qué hay en ellas y realizar acciones: buscar un producto, filtrar resultados, rellenar un formulario, reservar una cita o localizar un dato concreto. El problema es que la mayoría de webs modernas están pensadas para ojos humanos: mucho diseño visual, menús desplegables, botones hechos “a medida” y contenido que aparece y desaparece. Para un agente, esa web puede ser un laberinto.
Los resultados de la investigación lo dejan claro. El benchmark WebArena, diseñado para medir cómo se desenvuelven agentes en tareas reales en Internet, mostró que un agente basado en GPT-4 lograba un 14,41 % de éxito en tareas de principio a fin, frente al 78,24 % de una persona. No es que “la IA no pueda”, es que la web real es confusa cuando la estructura no ayuda.
¿Qué significa “HTML semántico” sin entrar en tecnicismos?
Una forma sencilla de verlo: el HTML es como la señalización de un edificio.
- Si un edificio tiene carteles claros (“Recepción”, “Ascensor”, “Salida”), cualquiera se orienta.
- Si todo son pasillos sin señales y puertas sin rótulo, hasta un humano se pierde. Un agente, más.
En una web, el “cartel” equivale a cosas tan básicas como:
- Que un botón sea un botón de verdad (y no una caja que parece botón).
- Que un campo de formulario tenga una etiqueta (“Correo electrónico”, “Código postal”).
- Que un menú esté marcado como navegación y el contenido principal como contenido principal.
- Que una imagen que aporta información tenga una descripción (texto alternativo).
Ese tipo de estructura es lo que usan los lectores de pantalla para ayudar a personas con discapacidad visual. Y, por extensión, también es lo que aprovechan muchos sistemas automáticos para entender “qué es qué”.
Por qué los agentes fallan cuando la web está “bien pintada” pero mal explicada
Los agentes suelen usar dos estrategias:
- “Ver” la página como si fuese una imagen (más costoso y menos preciso en detalles).
- “Leer” la estructura (más eficiente, pero depende de que la web esté bien etiquetada).
En la práctica, lo que más rompe a estos sistemas no es la falta de diseño, sino la falta de significado. Un ejemplo típico: un icono de lupa que visualmente es “Buscar”, pero que para un agente no tiene nombre; o un menú desplegable que cambia sin indicar que se ha desplegado.
Tabla rápida: cómo se vive la misma web según esté “bien explicada” o no
| Elemento en una web | Si está bien estructurado | Si está “disfrazado” (mal estructurado) | Qué pasa con agentes y lectores de pantalla |
|---|---|---|---|
| Botón “Comprar” | Es un botón real con texto claro | Es un bloque que parece botón | El agente lo encuentra y lo activa con fiabilidad / o se queda “buscando” |
| Campo “Email” | Tiene etiqueta (“Correo electrónico”) | Solo tiene un texto gris dentro (“placeholder”) | Aumentan errores al rellenar y validaciones fallidas |
| Menú de navegación | Está marcado como menú | Es un conjunto de enlaces sin contexto | Es más difícil orientarse y saltar a lo importante |
| Mensaje “Cargando…” | Se anuncia como estado | Solo aparece un spinner visual | El agente puede creer que no pasa nada y repetir acciones |
La idea es simple: cuanto más se parezca una web a un “texto bien organizado” (aunque sea visual), mejor la entienden humanos, máquinas y herramientas de apoyo.
El giro de 2026: cuando “ahorrar tokens” se vuelve un argumento de negocio
Aquí entra un punto que ya se está moviendo en el mercado: el coste de procesar páginas web con modelos de IA.
Cloudflare ha lanzado “Markdown for Agents”, una función que permite que, cuando un agente solicite una página con una cabecera estándar (Accept: text/markdown), Cloudflare convierta el HTML a Markdown en el edge y entregue una versión más “limpia” y estructurada. El objetivo: que los agentes consuman contenido con menos ruido y, en muchos casos, con menos gasto de tokens.
La documentación técnica de Cloudflare explica el mecanismo y muestra detalles relevantes para entender el concepto incluso sin ser técnico:
- La respuesta puede indicar un recuento estimado de tokens con una cabecera (
x-markdown-tokens). - Se usa negociación de contenido y se marca
vary: accept, para que la red no confunda versiones distintas (HTML vs Markdown). - Está disponible en planes Pro, Business y Enterprise (y también para SSL for SaaS), según su documentación.
Dicho de forma sencilla: es como pedir un mismo documento en dos formatos distintos, uno pensado para lectura humana (HTML) y otro para consumo eficiente por sistemas automáticos (Markdown).
Tabla sencilla: HTML “completo” vs Markdown “para agentes”
| Aspecto | HTML tradicional | Markdown para agentes |
|---|---|---|
| Para quién está pensado | Navegadores y humanos | Agentes y sistemas que procesan texto |
| “Ruido” típico | Menús, estilos, capas, elementos decorativos | Suele centrarse en el contenido estructurado |
| Coste de procesado en IA | Puede ser alto por complejidad | Puede reducir desperdicio de tokens |
| Riesgo | El agente interpreta con heurísticas propias | La conversión depende de cómo esté hecho el HTML |
| Control del sitio | Menos control sobre cómo “extrae” el agente | Más control si la conversión se sirve desde origen/edge |
Lo importante: no es “ser amigable con la IA”, es ser legible
La tentación sería pensar que esto va de “optimizar para bots”. Pero el mensaje de fondo es más amplio: la web necesita volver a ser legible por estructura, no solo por aspecto.
En un mundo donde parte del tráfico y de la atención puede venir mediado por agentes (resúmenes, recomendaciones, comparadores, automatizaciones), una web caótica no solo perjudica a la accesibilidad: también puede perjudicar a la comprensión, a la conversión y a cómo se interpreta la información. Y eso, para muchos negocios, es un problema real.
La paradoja es que la solución suele ser aburrida, pero efectiva: usar bien los elementos básicos, etiquetar, ordenar, y no esconder información clave en rincones “decorativos”. Si una web está bien construida para una persona que necesita ayudas de accesibilidad, también tiene muchas más papeletas de funcionar bien con agentes.
Preguntas frecuentes
¿Esto significa que las webs se tienen que rediseñar para la Inteligencia Artificial?
No necesariamente. La mayoría de mejoras son buenas prácticas antiguas: botones reales, formularios con etiquetas, menús claros y mensajes de estado comprensibles. Benefician a todo el mundo.
¿Qué es lo que más confunde a los agentes en una web moderna?
Controles sin nombre (iconos sin texto), botones falsos hechos con cajas genéricas, ventanas emergentes mal diseñadas y contenido que cambia sin avisar (spinners sin explicación, menús que aparecen sin indicarlo).
¿Markdown for Agents cambia Internet tal como se conoce?
Es un paso interesante: permite servir una versión más “consumible” por agentes usando una petición estándar. Pero no sustituye un HTML bien estructurado: la calidad de la conversión depende de cómo esté construido el contenido original.
¿Esto afecta solo a empresas grandes o también a webs pequeñas?
La tendencia afecta a todos, pero herramientas como la de Cloudflare tienen limitaciones de disponibilidad por plan. Aun así, las buenas prácticas de estructura y accesibilidad están al alcance de cualquier sitio, con o sin herramientas externas.